
The Library has begun a project to transcribe the six Registers which record borrowing for the period 1748-1800. This is the first step towards making the data digitally searchable and open to analysis.
To do this we have used the MediWiki platform with the Proofread Page extension to create a customized online transcription tool.
How it works:
- Transcribers can view document images alongside or above the transcription window, and can store canonical data about book titles in “linked to” pages.
- This data is then indexed by Solr and becomes searchable.
- The platform offers a full range of tools and characters and provides a protocol for monitoring page status. Pages can be flagged as “without text,” “problematic,” “not proofread” or “proofread.”
- Authors and titles are identified in Worldcat, and the permalink to the Worldcat record is given in most cases. This incorporates the unique OCLC identification number. The Library’s own catalogue (SAULCAT) is also checked, and if it seems possible that a volume is still available on the shelf, a link to the catalogue record is given.
- Information in the Borrowing Registers is never sufficient to identify a particular edition or printing of a volume, so the Worldcat search will aim only to confirm a correct title and a “nearest guess” publication date.
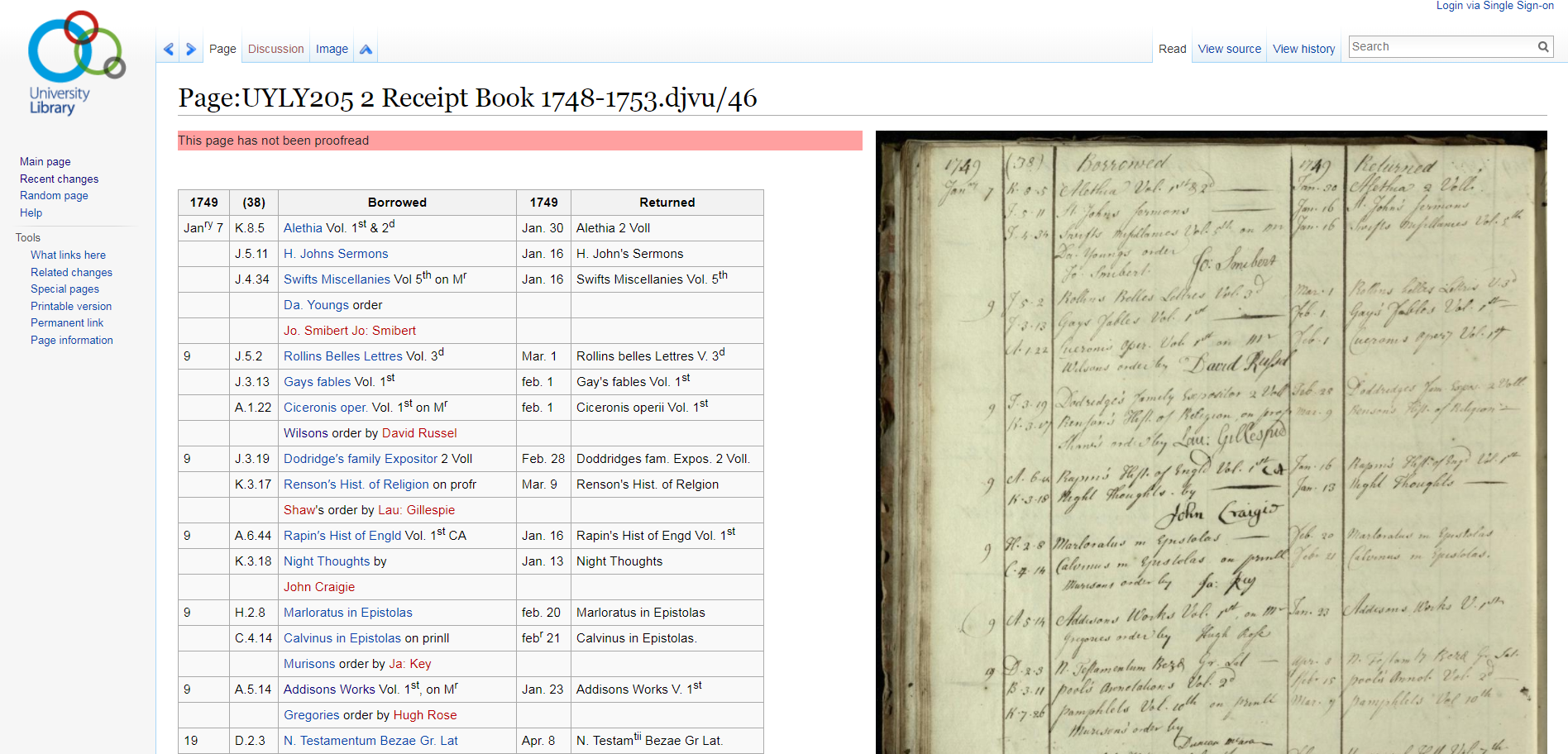 The Registers were transcribed so far:
The Registers were transcribed so far:
- UYLY205/2: Receipt Book 1748-1753
- UYLY206/1: Receipt Book 1773-1782
- UYLY206/4: Receipt Book 1791-1800
Digital Humanities intern Caitlin Price describes her experience of tackling the transcription task in summer 2016: https://standrewsrarebooks.wordpress.com/2016/08/11/digital-humanities-internship/ (Echoes from the Vault Blog, 11.08.16).
Library school intern Elena den Brok from Cologne University of Applied Sciences and graduate trainee Elizabeth Antell continued the Transcription Project in 2017-2018.
The project is managed by the library’s Digital Humanities and Research Computing team.